1. Ablauf des Importvorgangs#
Die Importschnittstelle wurde als ein kommandozeilenbasiertes Tool umgesetzt, welches darauf ausgelegt ist, einen automatischen, nicht-interaktiven Import durchzuführen. Um dies zu erreichen, müssen bestimmte Voraussetzungen erfüllt werden, die in diesem Abschnitt anhand des Importablaufes erläutert werden.
Das Tool wurde in der Skriptsprache Python implementiert und ist in der Lage, zusätzliche, kundenspezifische Python-Dateien zu laden, die ein abweichendes Verhalten oder zusätzliche Funktionalitäten der Importschnittstelle hinzufügen.
Der Ablauf eines automatischen Imports wird über die nachfolgenden Schritte skizziert:
Die zu übernehmenden Benutzerdaten müssen automatisch oder manuell aus dem Quellverzeichnis exportiert und als Datei gespeichert werden.
Für den Import muss vorab einmalig eine Konfigurationsdatei erstellt werden, die bei jedem weiteren Import wiederverwendet werden kann. Die Konfigurationsdatei ermöglicht es dem Importtool ucs-school-user-import, die exportierten Daten einzulesen und die Eingabedatensätze (Benutzerdaten) konkreten UCS@school-Benutzern im LDAP-Verzeichnisdienst zuzuordnen.
Die Importschnittstelle unterstützt zwei unterschiedliche Modi, die festlegen, ob die Eingabedatensätze als neuer Soll-Zustand oder als inkrementelles Update zum Ist-Zustand interpretiert werden sollen.
- Neuer Soll-Zustand
Im ersten Fall werden die Eingabedatensätze als neuer Soll-Zustand verwendet. Dazu wird ein automatischer Abgleich zwischen den UCS@school-Benutzern im LDAP-Verzeichnisdienst und den übergebenen Eingabedatensätzen durchgeführt, um zu ermitteln, welche UCS@school-Benutzer im LDAP-Verzeichnisdienst angelegt, modifiziert oder gelöscht werden müssen, um den neuen Soll-Zustand zu erreichen.
- Inkrementelles Update zum Ist-Zustand
Im zweiten Fall findet kein automatischer Abgleich statt. Stattdessen muss bei jedem Eingabedatensatz speziell vermerkt werden, ob die dazu passenden UCS@school-Benutzer im LDAP-Verzeichnis angelegt, modifiziert oder gelöscht werden. Dieser teilautomatische Ansatz erfordert erheblich mehr Prozesslogik bei der Bereitstellung der Eingabedatensätze, da die entsprechenden Teile in der Importschnittstelle deaktiviert sind.
Je nach Konfiguration werden die Werte des Eingabedatensatzes nach dem Einlesen automatisch geprüft, modifiziert und/oder erweitert. Darunter fällt z.B. auch die automatische Zuweisung eines eindeutigen Benutzernamens oder die Generierung einer E-Mailadresse.
Während des vollständigen Einlesens und Verarbeitens der Eingabedatensätze werden noch keine Änderungen am LDAP-Verzeichnis vorgenommen. Sind alle Eingabedatensätze verarbeitet, werden im Anschluss die notwendigen Änderungen am LDAP-Verzeichnis durchgeführt: UCS@school-Benutzer werden gelöscht, verändert oder angelegt.
Neuen UCS@school-Benutzern werden während des Imports automatisch sichere, zufällige Passwörter zugeteilt. Da Passwörter im LDAP-Verzeichnis grundsätzlich nicht im Klartext vorliegen und somit später nicht mehr ausgelesen werden können, werden die Passwörter für neue Benutzer, sofern explizit konfiguriert, in einer speziellen CSV-Datei abgelegt.
Nach den erfolgten Änderungen am LDAP-Verzeichnis wird abschließend ein Bericht in Form einer CSV-Datei erzeugt, mit dessen Hilfe sich schnell die Eingabedaten und die durch sie verursachten Änderungen sowie eventuell aufgetretene Probleme nachvollziehen lassen.
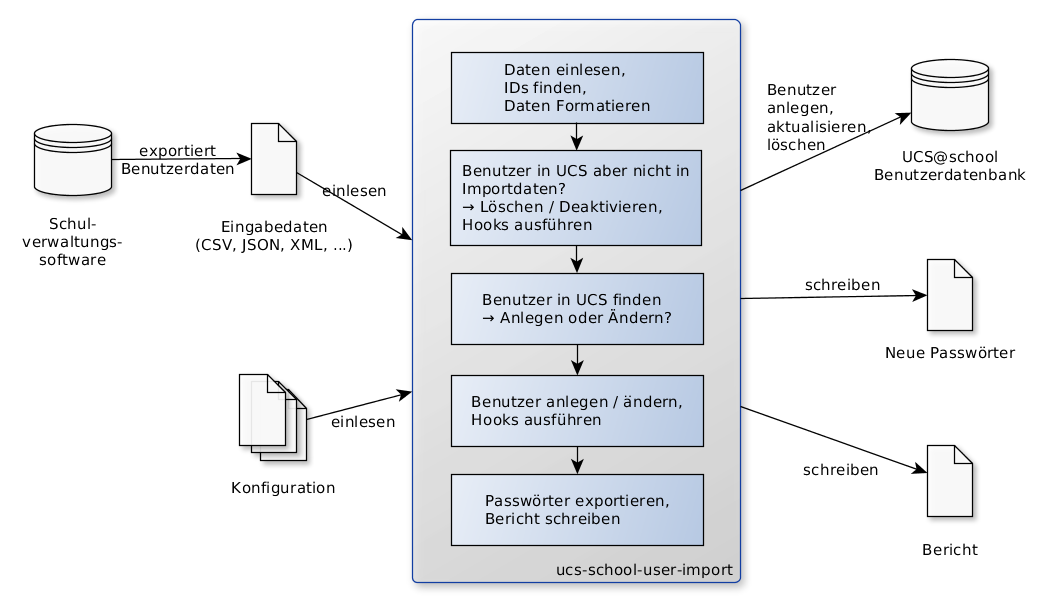
Abb. 1.1 Ablauf eines Benutzerimports#
Für die Analyse von Problemen wird während des gesamten Imports ein Protokoll
über alle technischen Vorgänge in Logdateien mit unterschiedlichen Detailtiefen
geführt. Wenn nicht anders konfiguriert, sind das die Dateien
/var/log/univention/ucs-school-import.log und
/var/log/univention/ucs-school-import.info.
1.1. Datenformate#
Die Importsoftware kann gegenwärtig Daten nur aus CSV-Dateien einlesen. Wie eine Unterstützung für weitere Dateiformate (z.B. JSON, XML etc.) hinzugefügt werden kann, kann Erweiterung um neue Funktionalität entnommen werden.
1.2. Kodierung#
Momentan sind die folgenden Kodierungen unterstützt:
ISO-8859-1
ASCII
UTF-8
UTF-16
Hinweis
Im Fall von UTF-16 werden ausschließlich solche Kodierungen unterstützt, welche eine Byte-Reihenfolge-Markierung (BOM) beinhalten. Wird eine UTF-16 Datei ohne BOM eingegeben bricht der Import ab.
Falls eine nicht unterstütze Kodierung erkannt wird, schlägt der Import mit einem
UnsupportedEncodingError fehl. Andere Kodierungen können
mit einer benutzerdefinierten Implementierung eines CsvReaders unterstützt werden, siehe
Erweiterung um neue Funktionalität.
1.3. Zuordnung von Benutzern des Quellverzeichnisses zu UCS@school-Benutzern#
Das Tool ucs-school-user-import unterstützt den Import von
Benutzerdaten aus mehreren Quellverzeichnissen. Um jeden UCS@school-Benutzer einem
Benutzer in einer Quelldatenbank eindeutig zuordnen zu können, werden am
UCS@school-Benutzerobjekt zwei zusätzliche Attribute gespeichert: source_uid
und record_uid.
source_uidDie
source_uidist ein eindeutiger Bezeichner für die Quelldatenbank von der ein Benutzer importiert wurde. Der Bezeichner kann frei gewählt werden und muss für jede Quelldatenbank eindeutig sein. Er ist während des Imports auf der Kommandozeile bzw. in der Konfigurationsdatei für jede Quelldatenbank explizit mit anzugeben.record_uidDie
record_uidist ein eindeutiger Bezeichner für den Benutzer in der Quelldatenbank. Als Bezeichner kann z.B. auf vorhandene Attribute innerhalb der Quelldatenbank, wie z.B. eine Schüler- oder Mitarbeiternummer, zurückgegriffen werden. Sollte kein eindeutig identifizierendes Attribut in der Quelldatenbank vorhanden sein, kann auch durch die Konkatenation von mehreren Attributen der Quelldatenbank ein eineindeutiger Bezeichner generiert werden.
Durch die Kombination dieser beiden Bezeichner kann ein UCS@school-Benutzer genau einem Benutzer in einem bestimmten Quellverzeichnis zugeordnet werden.
Vorsicht
source_uid und record_uid müssen eindeutig und unveränderlich sein,
sonst werden UCS@school-Benutzer beim Abgleich mit den Eingabedaten nicht
gefunden und ggf. gelöscht bzw. es werden die falschen
UCS@school-Benutzerobjekte modifiziert.
Mit Hilfe der beiden Bezeichner source_uid und record_uid wird versucht,
jeden Eingabedatensatz genau einem UCS@school-Benutzer zuzuordnen:
Wurde kein UCS@school-Benutzer mit passenden Bezeichnern im LDAP-Verzeichnis gefunden, wird ein neuer UCS@school-Benutzer auf Basis des Eingabedatensatzes erstellt.
Existiert ein passender UCS@school-Benutzer bereits, wird er von ucs-school-user-import modifiziert. Die Importsoftware gleicht die Eingabedaten mit dem LDAP-Verzeichnisdienst ab und passt den UCS@school-Benutzer entsprechend dem Eingabedatensatz an.
Während des Abgleichs wird auch geprüft, ob im LDAP-Verzeichnis UCS@school-Benutzer der betreffenden Quelldatenbank vorhanden sind, die in den Eingabedatensätzen nicht mehr vorhanden sind. Die betroffenen UCS@school-Benutzer werden dann automatisch gelöscht.
Vorsicht
Wird vom früheren Import Skript zum Neuen migriert, muss beachtet werden,
dass je nachdem welche Version zuvor benutzt wurde, an den Benutzerobjekten
entweder keine source_uid gespeichert wurde, oder der Wert
LegacyDB hinterlegt ist.
Beispiele:
Die Schulen eines Schulträgers verwenden voneinander unabhängige Verwaltungssoftware. Die Software exportiert für jede Schule separate CSV-Dateien für den Import. Es wird je eine Datei für Schüler, Lehrer, Mitarbeiter und Sorgeberechtigte erzeugt. Für den Import der CSV-Dateien wird pro Schule und Benutzerrolle eine separate Konfiguration mit individueller
source_uidbenötigt. Sind die Konfigurationen hinreichend ähnlich, können die gleichen Konfigurationsdateien verwendet werden und die sie unterscheidenden Optionen an der Kommandozeile gesetzt werden. Sollten sich nursource_uidund Benutzerrolle unterschieden, so würde der Import mit den entsprechenden Optionen z.B. so aufgerufen:$ /usr/share/ucs-school-import/scripts/ucs-school-user-import \ --conffile <gemeinsame Konfigurationsdatei> \ --source_uid <Schulname>-<Benutzerrolle> \ --user_role <Benutzerrolle> \ --infile <CSV-Datei>
Durch die Verwendung von
<Schulname>-<Benutzerrolle>(z.B.GSMitte-student) alssource_uidwird ein eindeutiger Bezeichner pro Schule und Benutzerrolle sicher gestellt.Added in version 4.2v4: Ab UCS@school Version 4.2 v4 wird nur eine
source_uidpro Schule benötigt (-<Benutzerrolle>kann weggelassen werden), sofern mit--user_roledie Benutzerrolle angegeben wird.In diesem Szenario ist die Verwendung schulübergreifender Benutzerkonten nicht möglich, weil dafür eine gemeinsame
source_uidder beteiligten Schulen benötigt wird.Ein Schulträger verwendet eine Software für die Verwaltung aller seiner Schulen. Die Software exportiert für jede Benutzerrolle eine CSV-Datei. In diesen Dateien sind alle Benutzer aller Schulen (von der jeweiligen Rolle) enthalten. Für den Import der CSV-Dateien wird nur pro Benutzerrolle eine separate Konfiguration mit individueller
source_uidbenötigt, bzw. die gleiche Konfigurationsdatei und an der Kommandozeile wird gesetzt:--source_uid <Benutzerrolle>.Added in version 4.2v4: Ab UCS@school Version 4.2 v4 wird keine separate
source_uidmehr pro Benutzerrolle benötigt. Es reicht dann eine Konfigurationsdatei mit einer darin eingespeichertensource_uidfür alle Importvorgänge, sofern mit--user_roledie Benutzerrolle angegeben wird.In diesem Szenario ist die Verwendung schulübergreifender Benutzerkonten möglich, weil Benutzer mit der gleichen Rolle an allen Schulen die gleiche
source_uidhaben.Ein Schulträger verwendet eine Software für die Verwaltung aller seiner Schulen. Die Software exportiert alle Benutzer in eine CSV-Datei. In dieser Datei sind Benutzer aller Rollen und aller Schulen enthalten. In der CSV-Datei gibt es eine Spalte in der steht, welche Rolle der jeweilige Benutzer hat. Für den Import der CSV-Dateien wird nur eine Konfigurationsdatei mit einer darin eingespeicherten
source_uidbenötigt. Um die Benutzerrolle auszulesen, wird der entsprechenden Spalte der Sonderwerte__rolezugeordnet (siehe als Beispiel die Konfigurationsdatei/usr/share/ucs-school-import/configs/ucs-school-testuser-import.json).In diesem Szenario ist die Verwendung schulübergreifender Benutzerkonten möglich, weil alle Benutzer die gleiche
source_uidhaben.